 SangyaPundir [CC BY-SA 4.0], from Wikimedia Commons
SangyaPundir [CC BY-SA 4.0], from Wikimedia Commons
The FAIR principles are a useful framework for thinking about sharing data in a way that will enable maximum use and reuse. They provide guidance for data producers and publishers to enhance the reusability of research data and were developed by the FORCE11 community.
The FAIR principles concern the reuse of data, but that data does not have to be open. Funders, such as EU and UKRI are promoting FAIR data and now require researchers to work towards adopting the FAIR principles.
Working towards making your data FAIR is beneficial to you as a researcher because it achieves the maximum impact for your research, increases visibility and possible citations, can improve reproducibility and reliability and can attract new and different partnerships. Your research data can also enable new research questions to be answered.
FAIR relates to both your research data and metadata.
Metadata is needed to enable data to be found, reused and managed, and to understand the context of your data and files. Metadata provides a description of who is the responsible researcher; as well as when, where and why the data was collected and how the data can be cited. Metadata is often guided by a specific discipline and/or repository through the use of metadata standards.
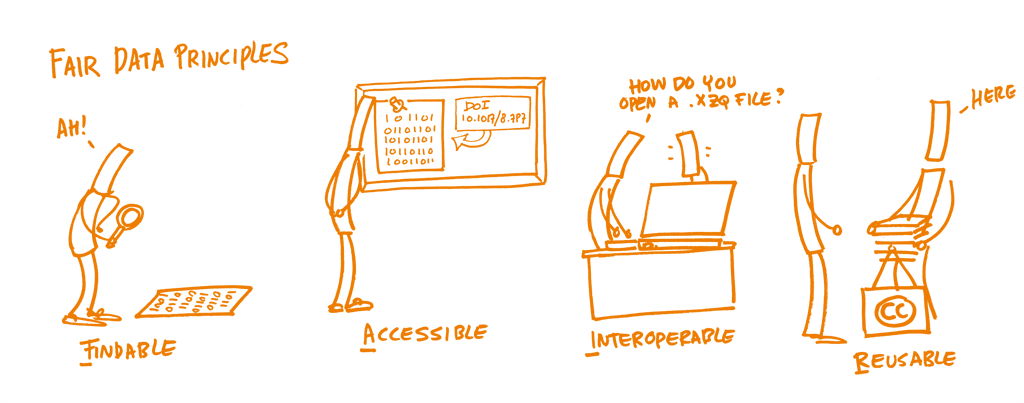
Findable
Both the metadata and your datasets should be easy to find for both humans and computers. Machine-readable metadata are essential for automatic discovery of datasets and services.
What does this mean?
That your data are described with metadata; that your data and metadata have a global unique persistent identifier; that your data and metadata are registered or indexed in a searchable resource, a research data repository.
What to do
You need a unique persistent identifier and many data repositories assign a persistent identifier. Use a trusted or discipline specific repository to upload your data and/or metadata. They use persistent identifiers and will require relevant metadata to be assigned to your data and persistent identifier. As does the Liverpool Research Data Catalogue which mints DOIs.
Accessible
Not only should your data and/or metadata be findable, both humans and machines need to gain access. As FAIR does not necessarily mean openly sharing, this could be under specific conditions. Even so, it is still possible to make the metadata publicly available.
What does this mean?
If you cannot share your data openly, the metadata should be available openly, detailing how the data can be shared in controlled or limited way. Available via a specific data repository or Liverpool Research Data Catalogue
That your metadata and data (if appropriate) is assigned a persistent identifier (such as a DOI).
What to do
If you can share your data openly then deposit your data in the Liverpool Research Data Catalogue, a discipline specific research data catalogue or well-known general catalogue, such as Zenodo, FigShare, or Dryad.
If you cannot share openly, create a metadata record only, which includes under what conditions the data can be shared. Some research data repositories will manage access for you (UKDS) usually these repositories are discipline specific. Otherwise, access has to be managed by yourself and/or Department. Email the RDM Team if you are considering this route.
Interoperable
As the aim is to speed up discover and uncover new insights, research data should be easily combined with other datasets, applications and workflows by humans and computer systems.
What does this mean?
You should use whenever possible, well-known and preferably open formats and software. Relevant standards for metadata and community agreed schemes, vocabularies, keywords, ontologies where possible.
What to do
Provide a read me file that describes your process, a description of each file, a data dictionary if appropriate and details of any data and code held elsewhere. Provide details that if you were looking back at what you had done in say 5 years’ time, you yourself would need to know. Be consistent in your file names, data variables, scripts, scripts variables and throughout similar annotations.
Consider the software/application you are using in presenting the data. Well known and used discipline specific software packages are best. If using specialist new and/or expensive software then consider reformatting to a more user-friendly application, if feasible.
Reusable
Research data should be ready for future research and future processing, making it clear that findings can be replicated and the data/results can be used to build/develop new research questions.
What does this mean?
That there is proper documentation to support interpretation of the data. That there is a clear and accessible data usage licence and that is clear how, why and by whom the data have been created and processed and that the data/metadata meets relevant domain standards.
What to do
Data should be accompanied by documentation, covering item level notes on the names and meanings of variables, explanation of how all the files that make up the dataset relate to one another (if appropriate) and details explaining the aims of the study, the hypothesis behind it, the instruments (if applicable) and the methodology. Always link to original journal articles (which can provide such details) and subsequent outputs.
There should be a clear license to govern the terms of reuse, such as the Creative Commons licence or The Open Government Licence (OGL) or GNU licence for software.