FunTuple: LHCb's new innovation for offline data processing
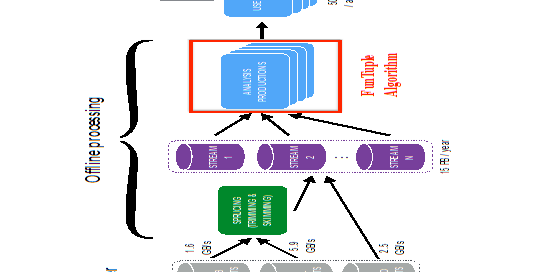
Figure: Data flow diagram for Run 3 data processing showing the placement of the FunTuple algorithm.
In anticipation of Runs 3 and 4 of the Large Hadron Collider (LHC), the LHCb experiment has been revamping its offline software framework to tackle imminent data processing challenges. A recent paper by a team of eight experts introduces FunTuple, an innovative algorithm tailored for offline data processing within LHCb.
FunTuple efficiently computes and stores a wide range of observables for both reconstructed and simulated events. Its distinctive feature is seamless integration, ensuring consistency between trigger-computed and offline-analysed observables through shared tools, while offering users the ability to fully customise the sets of stored observables — all backed by rigorous and continuous reliability validation.
Eduardo Rodrigues, Senior Research Physicist at the University of Liverpool and the leader of the LHCb Data Processing and Analysis project, expressed his enthusiasm about this significant milestone, stating: “As we embark on the journey through LHCb Runs 3 and 4, FunTuple is the powerful and flexible analysis tool that effectively creates curated data samples for the LHCb analysts.”
As illustrated in the figure below, the FunTuple algorithm plays a pivotal role in bridging the gap between the offline data processing stage (known as Sprucing) and the subsequent user analysis stages. With its innovative tools, FunTuple is set to be a crucial enabler for offline data processing within the LHCb experiment for the next decade and beyond.
For those interested in delving deeper into the technical details, the preprint of the paper is available at https://arxiv.org/abs/2310.02433, and it has been submitted to Computing and Software for Big Science (Springer).