
Mr Gautam Pal
Research Associate Communication and Media
Research
Multi-Agent Big-Data Lambda Architecture
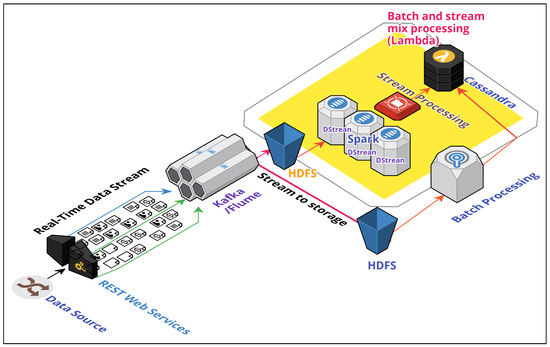
This research studies big-data hybrid-data-processing lambda architecture, which consolidates low-latency real-time frameworks with high-throughput Hadoop-batch frameworks over a massively distributed setup. In particular, real-time and batch-processing engines act as autonomous multi-agent systems in collaboration. The research proposed a Multi-Agent Lambda Architecture (MALA) for e-commerce data analytics. The framework addresses the high-latency problem of Hadoop MapReduce jobs by simultaneous processing at the speed layer to the requests which require a quick turnaround time. At the same time, the batch layer in parallel provides comprehensive coverage of data by an intelligent blending of the stream and historical data through the weighted voting method. The cold-start problem of streaming services is addressed through the initial offset from historical batch data. Challenges of high-velocity data ingestion are resolved with distributed message queues. A proposed multi-agent decision-maker component is placed at the MALA stack as the gateway of the data pipeline. We prove the efficiency of our batch model by implementing an array of features for an e-commerce site. The novelty of the model and its key significance is a scheme for multi-agent interaction between batch and real-time agents to produce deeper insights at low latency and at significantly lower costs. Hence, the proposed system is highly appealing for applications involving big data and caters to high-velocity streaming ingestion and a massive data pool.
Big Data Lifelong Learning

This work introduces a Lifelong Learning framework which constantly adapts with changing data patterns over time through incremental learning approach. In many big data systems, iterative re-training high dimensional data from scratch is computationally infeasible since constant data stream ingestion on top of a historical data pool increases the training time exponentially. Therefore, the need arises on how to retain past learning and fast update the model incrementally based on the new data. Also, the current machine learning approaches do the model prediction without providing a comprehensive root cause analysis. To resolve these limitations, the proposed framework lays foundations on an ensemble process between stream data with historical batch data for an incremental lifelong learning (LML) model.